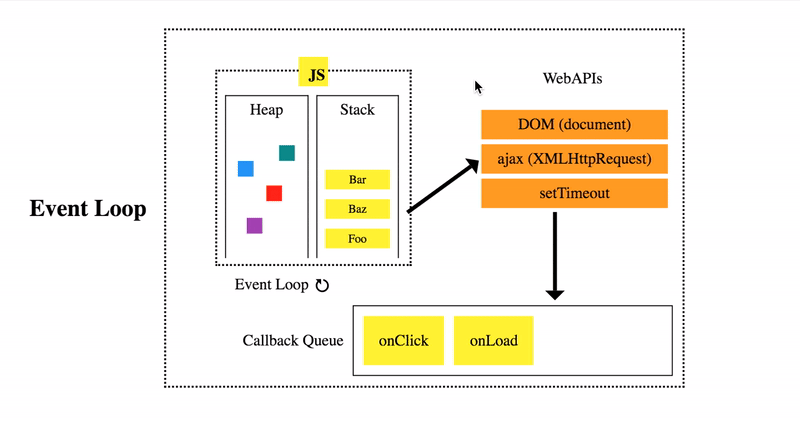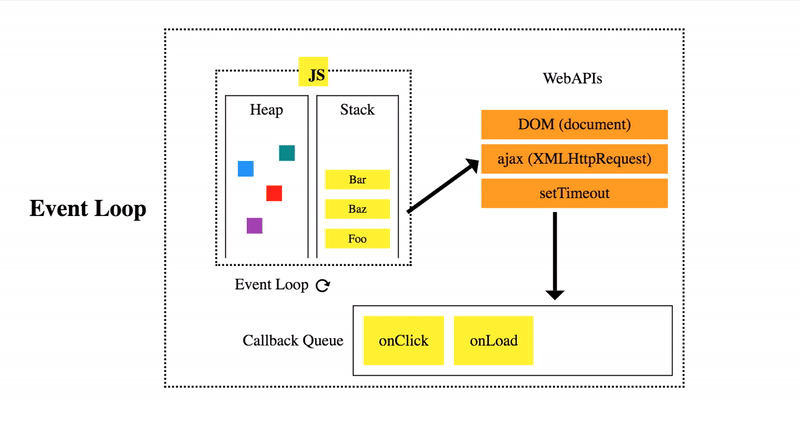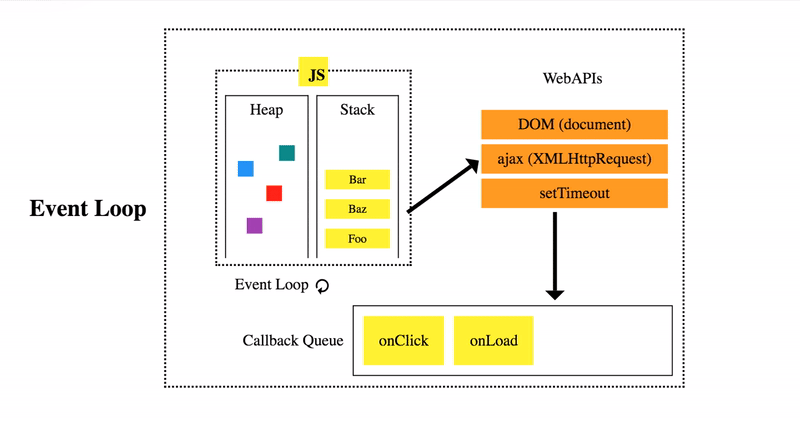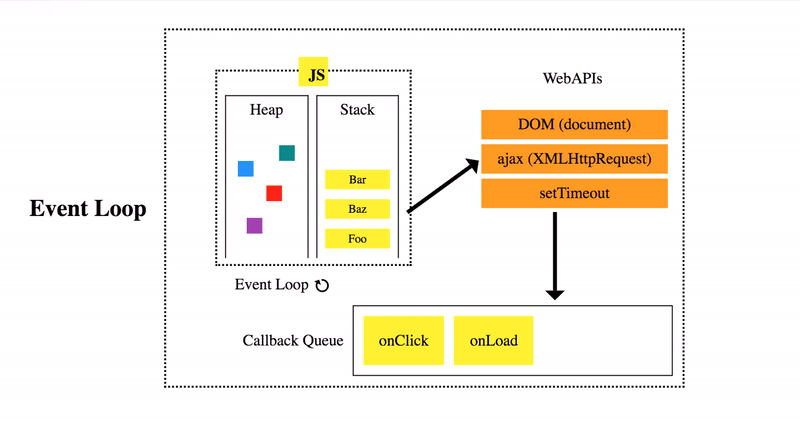
A new concept called the “Job Queue” was introduced in ES6. It’s a layer on top of the Event Loop queue. You are most likely to bump into it when dealing with the asynchronous behavior of Promises (we’ll talk about them too).
We’ll just touch on the concept now so that when we discuss async behavior with Promises, later on, you understand how those actions are being scheduled and processed.
Imagine it like this: the Job Queue is a queue that’s attached to the end of every tick in the Event Loop queue. Certain async actions that may occur during a tick of the event loop will not cause a whole new event to be added to the event loop queue, but will instead add an item (aka Job) to the end of the current tick’s Job queue.
This means that you can add another functionality to be executed later, and you can rest assured that it will be executed right after, before anything else.
A Job can also cause more Jobs to be added to the end of the same queue. In theory, it’s possible for a Job “loop” (a Job that keeps adding other Jobs, etc.) to spin indefinitely, thus starving the program of the necessary resources needed to move on to the next event loop tick. Conceptually, this would be similar to just expressing a long-running or infinite loop (like while (true) ..) in your code.
Jobs are kind of like the setTimeout(callback, 0) “hack” but implemented in such a way that they introduce a much more well-defined and guaranteed ordering: later, but as soon as possible.
Callbacks
As you already know, callbacks are by far the most common way to express and manage asynchronicity in JavaScript programs. Indeed, the callback is the most fundamental async pattern in the JavaScript language. Countless JS programs, even very sophisticated and complex ones, have been written on top of no other async foundation than the callback.
Except that callbacks don’t come with no shortcomings. Many developers are trying to find better async patterns. It’s impossible, however, to effectively use any abstraction if you don’t understand what’s actually under the hood.
In the following chapter, we’ll explore couple of these abstractions in-depth to show why more sophisticated async patterns (that will be discussed in subsequent posts) are necessary and even recommended.
Nested Callbacks
We’ve got a chain of three functions nested together, each one representing a step in an asynchronous series.
This kind of code is often called a “callback hell”. But the “callback hell” actually has almost nothing to do with the nesting/indentation. It’s a much deeper problem than that.
First, we’re waiting for the “click” event, then we’re waiting for the timer to fire, then we’re waiting for the Ajax response to come back, at which point it might get all repeated again.
At first glance, this code may seem to map its asynchrony naturally
So, such a sequential way of expressing your async code seems a lot more natural, doesn’t it? There must be such a way, right?
Promises
It’s all very straightforward: it sums the values of x and y and prints it to the console. What if, however, the value of x or y was missing and was still to be determined? Say, we need to retrieve the values of both x and y from the server, before they can be used in the expression. Let’s imagine that we have a function loadX and loadY that respectively load the values of x and y from the server. Then, imagine that we have a function sum that sums the values of x and y once both of them are loaded.
There is something very important here — in that snippet, we treated x and y as future values, and we expressed an operation sum(…) that (from the outside) did not care whether x or y or both were or weren’t available right away.
Of course, this rough callbacks-based approach leaves much to be desired. It’s just a first tiny step towards understanding the benefits of reasoning about future values without worrying about the time aspect of when they will be available.
Promise Value
Let’s just briefly glimpse at how we can express the x + y example with Promises:
There are two layers of Promises in this snippet.
fetchX() and fetchY() are called directly, and the values they return (promises!) are passed to sum(...). The underlying values these promises represent may be ready now or later, but each promise normalizes its behavior to be the same regardless. We reason about x and y values in a time-independent way. They are future values, period.
The second layer is the promise that sum(...) creates
(via Promise.all([ ... ])) and returns, which we wait on by calling then(...). When the sum(...)operation completes, our sum future value is ready and we can print it out. We hide the logic for waiting on the x and y future values inside of sum(...) .
Note: Inside sum(…), the Promise.all([ … ]) call creates a promise (which is waiting on promiseX and promiseY to resolve). The chained call to .then(...) creates another promise, which the returnvalues[0] + values[1] line immediately resolves (with the result of the addition). Thus, the then(...) call we chain off the end of the sum(...) call — at the end of the snippet — is actually operating on that second promise returned, rather than the first one created by Promise.all([ ... ]). Also, although we are not chaining off the end of that second then(...), it too has created another promise, had we chosen to observe/use it. This Promise chaining stuff will be explained in much greater detail later in this chapter.
With Promises, the then(...) call can actually take two functions, the first for fulfillment (as shown earlier), and the second for rejection:
If something went wrong when getting x or y, or something somehow failed during the addition, the promise that sum(...) returns would be rejected, and the second callback error handler passed to then(...) would receive the rejection value from the promise.
Because Promises encapsulate the time-dependent state — waiting on the fulfillment or rejection of the underlying value — from the outside, the Promise itself is time-independent, and thus Promises can be composed (combined) in predictable ways regardless of the timing or outcome underneath.
Moreover, once a Promise is resolved, it stays that way forever — it becomes an immutable value at that point — and can then be observed as many times as necessary.
It’s really useful that you can actually chain promises:
Calling delay(2000) creates a promise that will fulfill in 2000ms, and then we return that from the first then(...) fulfillment callback, which causes the second then(...)'s promise to wait on that 2000ms promise.
Note: Because a Promise is externally immutable once resolved, it’s now safe to pass that value around to any party, knowing that it cannot be modified accidentally or maliciously. This is especially true in relation to multiple parties observing the resolution of a Promise. It’s not possible for one party to affect another party’s ability to observe Promise resolution. Immutability may sound like an academic topic, but it’s actually one of the most fundamental and important aspects of Promise design, and shouldn’t be casually passed over.
To Promise or not to Promise?
An important detail about Promises is knowing for sure if some value is an actual Promise or not. In other words, is it a value that will behave like a Promise?
We know that Promises are constructed by the new Promise(…) syntax, and you might think that p instanceof Promise would be a sufficient check. Well, not quite.
Mainly because you can receive a Promise value from another browser window (e.g. iframe), which would have its own Promise, different from the one in the current window or frame, and that check would fail to identify the Promise instance.
Moreover, a library or framework may choose to vend its own Promises and not use the native ES6 Promise implementation to do so. In fact, you may very well be using Promises with libraries in older browsers that have no Promise at all.
Swallowing exceptions
If at any point in the creation of a Promise, or in the observation of its resolution, a JavaScript exception error occurs, such as a TypeError or ReferenceError, that exception will be caught, and it will force the Promise in question to become rejected.
But what happens if a Promise is fulfilled yet there was a JS exception error during the observation (in a then(…) registered callback)? Even though it won’t be lost, you may find the way they’re handled a bit surprising. Until you dig a little deeper:
It looks like the exception from foo.bar() really did get swallowed. It wasn’t, though. There was something deeper that went wrong, however, which we failed to listen for. The p.then(…) call itself returns another promise, and it’s that promise that will be rejected with the TypeError exception.
Handling uncaught exceptions
There are other approaches which many would say are better.
A common suggestion is that Promises should have a done(…) added to them, which essentially marks the Promise chain as “done.” done(…)doesn’t create and return a Promise, so the callbacks passed to done(..) are obviously not wired up to report problems to a chained Promise that doesn’t exist.
It’s treated as you might usually expect in uncaught error conditions: any exception inside a done(..) rejection handler would be thrown as a global uncaught error (in the developer console, basically):